
Bài nổi bật
Hệ thống kiểm tra lỗi chính tả tiếng Việt nhanh, chính xác
Deep Spelling được phát triển bởi nhóm tác giả là giảng viên và sinh viên Trường ĐH Tôn Đức Thắng (TPHCM).
Deep Spelling được phát triển bởi nhóm tác giả là giảng viên và sinh viên Trường ĐH Tôn Đức Thắng (TPHCM), có thể kiểm tra lỗi chính tả trên quy mô lớn, cho kết quả nhanh.
Nâng cao chất lượng soạn thảo văn bản
PGS.TS Lê Anh Cường, Trưởng phòng Thí nghiệm Xử lý ngôn ngữ tự nhiên và Khai phá tri thức, Khoa Công nghệ Thông tin, Trường ĐH Tôn Đức Thắng – Trưởng nhóm nghiên cứu cho biết, lỗi chính tả xuất hiện trong các văn bản có thể ảnh hưởng tới chất lượng của văn bản, gây cảm xúc tiêu cực ở người đọc. Trong một số trường hợp, đối với văn bản hay bản tin của các cơ quan Nhà nước, lỗi chính tả còn gây ra sự không chính xác về nội dung.
Lỗi chính tả xảy ra có thể do đánh máy gây sai âm tiết, nhầm lẫn phụ âm, dấu hỏi ngã, dùng phương ngữ, từ sai (cụm từ hay dùng sai một cách phổ biến), hoặc một số trường hợp đặc biệt hơn như viết thừa từ, thiếu từ, sai quy tắc viết tên riêng, cách đánh dấu thanh.
Bài toán kiểm lỗi chính tả tiếng Việt đã được nghiên cứu từ lâu trong cộng đồng nghiên cứu về trí tuệ nhân tạo và xử lý ngôn ngữ tự nhiên. Một số hệ thống ứng dụng cũng đã được xây dựng và thử nghiệm thực tế, tuy nhiên chất lượng chưa thực sự tốt khi dùng. Hệ thống phát hiện và sửa lỗi chính tả Deep Spelling ra đời nhờ ứng dụng công nghệ học máy tiên tiến nhất đồng thời với các cải tiến riêng mới cho ngôn ngữ tiếng Việt.
Ngoài các lỗi cơ bản thì lỗi chính tả trong thực tế thường đa dạng hơn, có thể là kết hợp của nhiều kiểu lỗi trên. Trong nhiều trường hợp không thể xác định được lỗi nếu không xét ngữ cảnh (các từ xung quanh), hoặc thậm chí phải xét ngữ cảnh rộng (ví dụ ngữ nghĩa cả câu) thì mới có thể xác định được lỗi và gợi ý từ viết đúng.
Vì vậy, xác định lỗi chính tả và gợi ý từ đúng là bài toán khó, và với các phương pháp truyền thống trước đây (sử dụng từ điển, luật và các phương pháp học máy thông thường) sẽ khó mà xây dựng được một hệ thống chất lượng tốt đủ dùng trong thực tế.
Giải pháp Deep Spelling được nhóm phát triển trên Transformer, mô hình hiện đại, hiệu quả nhất hiện nay cho hầu hết các bài toán xử lý ngôn ngữ tự nhiên bằng học máy.
Transformer được phát triển và sử dụng cho rất nhiều hệ thống NLP (Xử lý ngôn ngữ tự nhiên) hiện tại như dịch máy, nhận dạng giọng nói, hỏi – đáp tự động, phân tích quan điểm… của các công ty lớn như Google, Facebook, Baidu…
Thuận tiện cho người dùng
PGS.TS Lê Anh Cường cho biết, chức năng của Deep Spelling rất đa dạng. Hệ thống có khả năng kiểm tra phát hiện ra 6 loại lỗi gồm chính tả, thiếu từ, thừa từ, viết hoa, viết thường, dấu thanh và khoảng trắng.
Nhóm nghiên cứu cung cấp 3 phương thức sử dụng thuận tiện cho người dùng. Có thể sử dụng trên web do nhóm cung cấp. Ngoài việc soạn thảo trực tiếp hoặc copy nội dung văn bản để kiểm tra chính tả, người dùng có thể upload file văn bản dạng Text, dạng MS Word, dạng Pdf (textual) hoặc là link của một trang web.
Hoặc có thể tích hợp với phần mềm soạn thảo trên máy tính thông qua dịch vụ cung cấp của nhóm nghiên cứu. Người dùng có thể sử dụng Deep Spelling trực tiếp trong MS Word, tiện lợi trong quá trình vừa soạn thảo vừa kiểm tra chính tả.
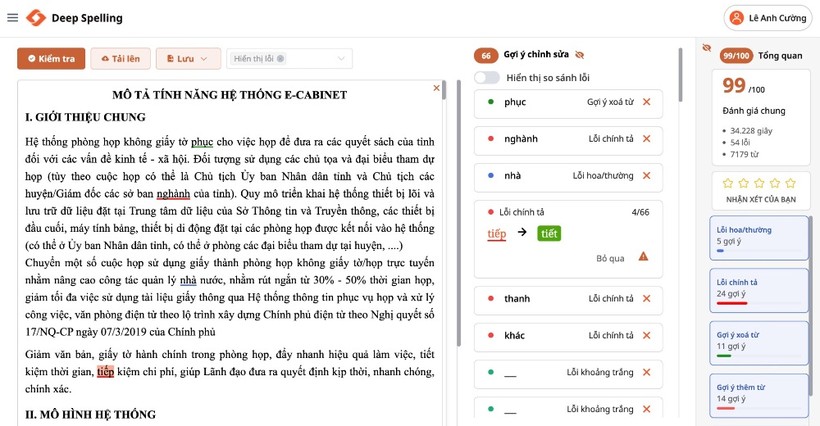
Hoặc có thể cài đặt hệ thống Deep Spelling trên server nội bộ (có thể trên từng máy nếu cấu hình máy đủ mạnh). Nhóm cung cấp một lựa chọn cho phép tổ chức sử dụng có thể cài đặt hệ thống trên server nội bộ để hoàn toàn bảo mật về dữ liệu.
Để so sánh kết quả thực nghiệm, nhóm nghiên cứu sử dụng hai chỉ tiêu là dự đoán từ lỗi, sửa và thay thế từ có lỗi. Với mỗi chỉ tiêu, nhóm sử dụng 3 độ đo là Precision, Recall và F-score.
Tập dữ liệu dùng để đánh giá là tập dữ liệu VSEC (VSEC2021/VSEC (github.com), được lấy ngẫu nhiên từ 618 tài liệu có lỗi chính tả trên trang tailieu.vn. Tập dữ liệu bao gồm 9.341 câu, trong đó có 11.202 lỗi chính tả thuộc 4.582 loại lỗi chính tả khác nhau.
Nhóm so sánh kết quả của Deep Spelling với 2 mô hình của nghiên cứu trên bao gồm VSEC và N-gram. Hệ thống VSEC của họ cũng sử dụng mô hình dựa trên Transformer, còn mô hình N-gram là theo tiếp cận dựa trên thống kê và luật.
“Kết quả của chúng tôi vượt trội trên hầu hết các chỉ tiêu, với độ đo F-score (tức độ đo tổng hợp) hơn từ 6 – 7% cho cả chỉ số detection (phát hiện lỗi) và correction (sửa lỗi). Một chi tiết thú vị là chỉ số Recall của chúng tôi vượt rất nhiều, hơn 12% ở nhiệm vụ detection và 13% ở nhiệm vụ correction. Điều này chứng tỏ Deep Spelling có khả năng phát hiện ra nhiều lỗi hơn, sửa được nhiều lỗi hơn trong khi vẫn đảm bảo độ chính xác cao”, PGS.TS Lê Anh Cường chia sẻ.
Để có nguồn dữ liệu cho hệ thống, nhóm của PGS.TS Lê Anh Cường đã thu thập số lượng văn bản tương đương khoảng 150 triệu câu, và sau đó sinh dữ liệu huấn luyện dựa trên các quy tắc và hiện tượng lỗi chính tả tiếng Việt. Nhóm nghiên cứu đã đưa hệ thống vào khảo sát một số bản tin trên một số trang web, tờ báo có uy tín ở Việt Nam. Thống kê được kết quả khả quan, những lỗi chính tả khó phát hiện đều được hệ thống nhận dạng một cách nhanh chóng.
Theo Nhật Chi / Báo Giáo dục & Thời đại
Xem thêm:
























